Using OpenAFS effectively
Course Handout: (last update 09 February 2011)
These notes may be found at http://www.dartmouth.edu/~rc/classes/afs. The online version has many links to additional information and may be more up to date than the printed notes
Using the OpenAFS filesystem effectively
The infrastructure provided by Research Computing at Dartmouth College
includes a central file storage system using OpenAFS.
For many users, the differences between files stored in OpenAFS
and local files are not important. However, there are some
differences in behaviour, and features not found in traditional desktop or Unix filesystems.
These notes are intended to explain the important differences from a user
perspective, and allow you to use the systems more safely, effectively and efficiently.
Throughout these notes, OpenAFS and AFS are used interchangeably.
Target Audience
All users of Research Computing central systems, Dartmouth RStor data volumes, Discovery,
PBS AFS systems, and anyone wishing to use AFS from a private computer.
Unless noted, these notes apply to any AFS installation. Where specific examples are given, they apply
to the Dartmouth Research Computing (northstar.dartmouth.edu) cell.
Topics Include
- An overview of AFS
- AFS clients, comparison to other network file systems
- Using AFS utility programs
- File I/O semantics; local file caching; performance issues
- AFS volumes and quotas
- The AFS filesystem layout
- Kerberos authentication and token lifetimes; background jobs
- Access Control (Permissions)
- Using groups for access control
- Backup snapshots
- Replicated volumes (RStor data volumes)
- Installing AFS clients
Assumptions
It is assumed that you already know how to:
- log in and get a command line window (any shell - command line tools operate similarly on
Unix/Linux, Mac OSX and Windows)
- run basic commands, make directories, navigate directories
Example commands are shown like this. Many commands
are shown with links to their online documentation
(fs)
Output from commands is shown like this
Optional items are shown in brackets, [ like this ]
Some descriptions in these notes have more detail available,
and are denoted like this:
More details of this item would appear here. The printed notes
include all of the additional information
These notes are updated from time to time. The "development"
set of notes are
http://northstar-www.dartmouth.edu/~richard/classes/afs
(Dartmouth only)
Richard Brittain, Dartmouth College Computing Services.
© 2010 Dartmouth College.
Comments and questions, contact Richard.Brittain @ dartmouth.edu


Table of Contents
(1)
AFS in a nutshell
AFS (originally Andrew File System)
is a distributed file and authentication service designed to be scaleable to
many client computers, using secure authentication and with flexible access control.
The main features are:
- Server functions can be distributed across multiple servers to spread load, add
redundancy and fault tolerance. This includes authentication and protection databases
in addition to file data. A collection of servers comprises a cell.
- Data may be moved between servers while active, and transparently to the end users.
- Servers may be brought on- and off-line while the system is active.
- Almost all administrative functions can be performed from any client.
- Scales well to many clients.
- All clients get an identical view of the entire cell.
- Flexible access controls; by user, group (user-managed) or machine (IP).
- Can replicate read-only volumes for redundancy
- Uses kerberos authentication to identify users and grant access to files. Client
computers are not trusted.
- Authentication process always encrypted. File contents optionally encrypted in transit.
- Client software is available for almost all Unix platforms, including Linux and Mac OS-X,
plus Microsoft Windows (2000 and later).
- Gateways to NFS, Windows 9x and Mac classic are available.
- Cross-cell operation is possible. AFS is a global filesystem.
- Developed by CMU, commercialized by Transarc, bought by IBM, branched into DFS/DCE, made open source
(OpenAFS.org).
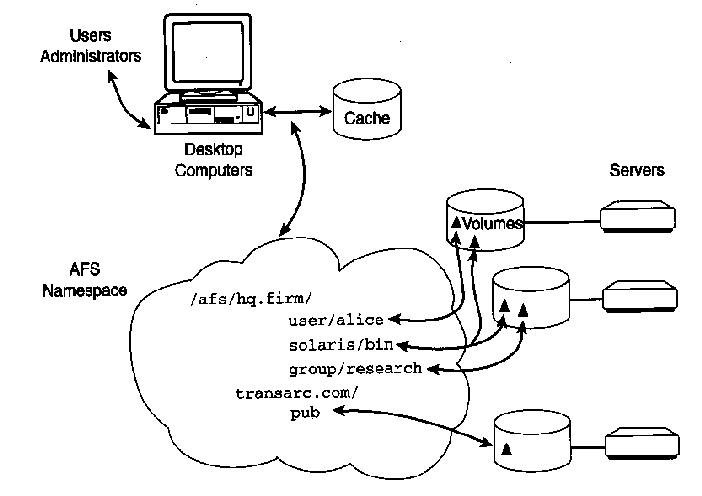 Figure1. AFS Overview
Figure1. AFS Overview
(2)
AFS from a user perspective
Centralized file systems like AFS provide a number of benefits to users,
including having a common user name and password for access to all client
computers in the cell (on which the user is defined).
Other benefits include a common home directory,
reduced need for file transfers,
increased file security and the elimination of the need to move home directories
as computers are retired.
In general AFS can be used in the same manner as a regular Unix
file system but the way in which permissions work can effect
how users manage their accounts. Users who run long jobs or disk
intensive jobs may also need to adjust the ways in which they work. People who
compile and run their own programs need to learn how to manage a single account shared between
multiple hardware platforms (e.g. a program compiled for Linux will not run under AIX)
- AFS client software runs on the user's workstation or compute server. The client
software implements a new filesystem type and diverts all file-related system calls.
- A client is a member of just one cell at a time, but can see other cells if mount
points have been configured for them.
- The AFS filesystem is conventionally mounted on
/afs.
All clients see the exact same filesystem tree below the mount point (cf NFS).
Clients can mount AFS at any desired point. /afs is conventional. Symbolic links may be made into AFS
to make more convenient pathnames. E.g. /ufac -> /afs/northstar.dartmouth.edu/ufac. The name
@cell is often a symlink to the cell name.
/afs/@cell -> /afs/northstar.dartmouth.edu/
- The top level of a particular cell is conventionally mounted below the AFS root, and is
named for the cell's full DNS name to ensure global uniqueness (e.g.
/afs/northstar.dartmouth.edu)
- The local AFS client implements caching of files and metadata.
Connections to AFS servers
are stateful, with callbacks from the servers to maintain cache coherency. The cache may be maintained
in memory or on disk (more common). (cf NFS). Clients may be tuned for cache size, file size,
expected network traffic etc.
- Users identify themselves to the system with a secure (kerberos-based) password. A limited-lifetime
token is granted (25 hour default lifetime). This process is usually integrated with the initial
login to the system. It can be performed as a separate step if needed, allowing for the client usernames
to be unrelated to the AFS names.
- With integrated login and authentication, users will use the same username and password to log in
to any client computer to which the username is known. This gives simplicity of account maintenance
and user training. (cf NFS/NIS). The actual passwords are stored in a replicated database on the AFS
servers.
- AFS can be used without authentication to distribute publicly readable files.
(3)
AFS user utility programs
Several utility programs are provided for managing volumes, permissions, passwords etc.
Most are used only by administrators, but a few are useful to all users. The utilities
are a little idiosyncratic compared to most Unix tools. The user interface does not always
follow unix conventions. No widely used menu-driven interface exists.
The tools are conventionally located in /usr/afsws/bin, which must be added
to the standard $PATH setting. On Linux they may be in /usr/bin.
There are a small number of utilities, but a large number of subcommands which can be performed (via
command line arguments).
Some subcommands require special priviledges. Some locally written wrapper scripts or aliases
may be provided for the most commonly used commands.
The main utilities of interest to users are:
klog
- Identify the user to the system (requests password) and generate a token. Usually integrated
with the system login procedure. Use to refresh a token at any time after logging in.
tokens
- Display currently held tokens and their expiration times
pagsh
- Start a new Process Authentication Group (PAG). Usually integrated
with the system login procedure. Explicitly needed when
working in multiple cells or as multiple users.
fs
- Filesystem queries. Used to examine and set quotas, local cache parameters, access control etc.
pts
- Protection database tool. Used to manage users and groups for Access Control Lists (ACLs).
kpasswd
- Password changing facility. Often combined with the standard Unix
passwd utility.
(4)
Differences in filesystem semantics
AFS makes some minor changes to the behaviour of the Unix filesystem calls to
improve performance. Many users can ignore the differences, but the behaviour
may make a difference when multiple programs try to access the same files.
AFS implements write on close to improve the efficiency of the local
cache. This means that when a file is opened for writing, data is first written
to the local cache, and the server copy is not updated until the file is closed.
Another process on the same client can see the partially written file.
The client cache manager can be tuned to improve performance for particular
types of files.
The initial open (for read or write) of a file entails database lookups to
determine the volume location and permissions. The file and metadata are copied to local cache and
then made available to the application.
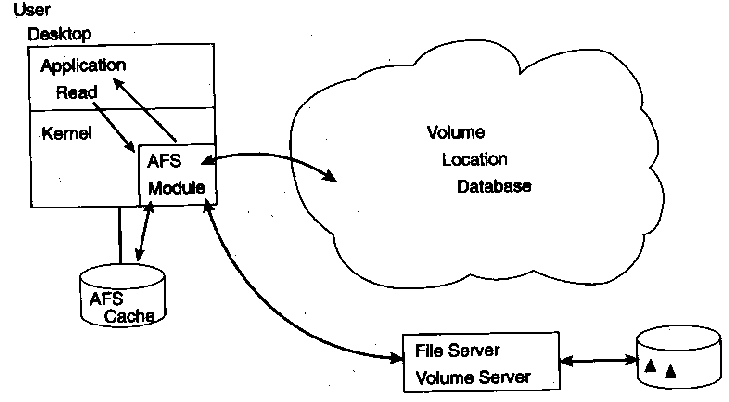
Figure 2. Client read - initial connection.
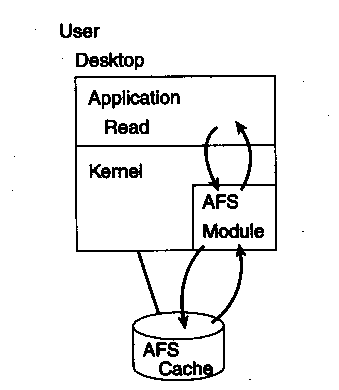
Figure 3. Client read - subsequent open of same file.
If reading, the AFS server will tell the client (callback) if the
server copy of the file changes. If it is unchanged, subsequent reads of the same file
involve only local disk cache and so are much faster.
Read/write Performance is very dependant on the client hardware speed and
cache configuration. Very occasionally problems might arise due to cache inconsistencies.
The following commands (subcommands of fs) can be used to remove stale
cache data.
fs_flush
- Flush named files or directories from the local cache
fs_flushvolume
- Flush all data from a particular volume
-
I/O intensive jobs
Writing and reading large amounts of data to a file can cause
performance problems for some programs if the file resides on a remote server.
AFS is generally optimized for robustness and scaleability rather than
high performance, and in some circumstances users may need to resort to using
local disk for large data files to get the best possible performance.
Scratch or temporary files used by programs should in most circumstances be
placed on local disk for best performance. Sometimes applications may default to writing
scratch files in the user's home directory, but can be configured to use other locations.
Permission bits
The traditional Unix permission bits are largely ignored by AFS. Only the user write and
execute bits are meaningful. All other access control is determined by the directory ACL.
Special files
AFS does not support device special files or named pipes.
(5)
AFS Authentication
The action of authenticating to a particular computer, and authenticating to AFS,
are usually combined so that only one username and password are required. This requires
that AFS usernames are used as the local usernames. No local password is used.
In most cases enabling an AFS account on a client computer requires only creating a
record in /etc/passwd, so account maintenance is greatly simplified.
Once the user has been identified
by the AFS system they are then allowed to use the computer and
access the files in their home directory.
The main difference between an AFS user and a local user is that the AFS
user is not tied or attached to a particular computer but
instead has a global identity that allows the user to authenticate to
multiple computers.
Computers can also use AFS without integrating the login procedure. In this case
a local login is performed as usual and then the user runs
klog -setpag to authenticate to AFS.
The -setpag option is used to generate a new PAG at the same time
as authenticating. The pagsh command can also be used for this.
Without a PAG, the token is attached to the local Unix UID of the user, which opens
a security hole since local root processes could 'su' to the user and inherit
the AFS token.
AFS token generation can also be integrated with other kerberos-based authentication
schemes (e.g. the DND), but this is not currently used at Dartmouth.
AFS tokens
An important component of the authentication process is the
granting of a token that is associated with the current
process group (or login session).
Tokens can be thought of as temporary identity cards that
can be used to assure that a user's process does indeed have the
correct permissions to access particular files. Tokens are based on Kerberos
and have a finite lifetime (default 25 hours in the Northstar cell).
The lifetime can be adjusted (per user), up to 30 days, but not eliminated
completely. It is a design decision to increase system security.
When a token expires, the user is still logged in and can run programs, but
loses access priviledges (becomes a guest user in effect), so file read/write
actions may fail.
The klog command can be used to renew a token at any time. The
token applies to all programs in the same Process Authentication Group (PAG).
With integrated logins, the PAG is a login session. The effect of this is that you may have
multiple programs and shell windows associated with the same token, and refreshing the token
in any one of them affects all the others.
The command tokens can be used to check the status and expiration times
of your tokens. Only one token can be held at a time for a given cell in a given PAG. This is a
consequence of the kerberos system and if it were not true, there would be ambiguity in
the access control. However, if a user has an account in multiple cells, a separate token
for each cell can be held.
Example: klog -cell thayer.dartmouth.edu
Separate PAGs can be started from a single login session to allow programs to run authenticated as different
users, but typically this facility is only needed by administrators.
Discarding tokens
The command unlog explicitly discards one or more tokens. It is usually performed automatically
when logging out, for added security.
AFS home directories
The major difference between an AFS home directory and local home
directories is that an AFS home directory is shared between multiple computers.
The user account is detached from the computer, making it much easier to
retire old computers and bring new ones online.
A complicating factor is that the shared home directory may be used for
different operating systems (Linux, Solaris, Irix etc.) and so common configuration files
like .cshrc and .login must be carefully crafted to produce the correct results
on all operating systems in use.
Local (unauthenticated) processes on a computer cannot typically read or write files in a home directory.
This is a problem for certain software such as mail delivery (forwarding, vacation messages, procmail) and
cron jobs. Workarounds are usually possible. For example, if all mail delivery is performed
only by a trusted computer (used for no other purpose), then that computer can be given special access.
Long running jobs
- If your jobs might run for more then 24 hours contact the system manager
to request a longer default token lifetime.
- Run
klog to refresh your token before starting a long job
- Keep a terminal window open in which you can periodically (daily) run the
klog command
to refresh your token. Users who login each day do
not need to use the "klog" command as they will receive a
new token at each login.
- If backgrounding a process and logging out, be sure that your account does not run
unlog at logout.
Changing passwords
The kpasswd command is the AFS equivalent of the system passwd command.
It may be integrated with passwd for users with AFS homes.
There are cell-specific options on acceptable passwords, password lifetimes, bad password lockouts etc.
(6)
AFS Volumes
An AFS volume is analogous to a filesystem on a logical partition.
Volumes are mounted at some point in the AFS filesystem
hierarchy, at which point they become available to client computers.
Volumes are the unit of AFS server space for transactions such as creation,
deletion, migration between servers, replication, and backups.
Volumes can be any size up to the physical size of the server disk partitions,
but many operations on volumes are easier if the size is kept smaller.
Volumes may be mounted anywhere in AFS space, including multiple mount points
(although this is confusing). Disk quotas are applied at the volume level.
The command to check on the current quota status is subcommand listquota
to fs, i.e. fs_listquota.
The ACL (Access Control List) at the top level of the volume is
important, since it may be mounted in a location with less restrictive
parent ACLs than intended. For example, a user volume might be
inaccessible to unauthenticated users by being mounted below a private
directory. If the volume itself allows public read, it may be re-mounted
inside a public directory and lose the protection.
Typically we use:
- One volume per user account for the home directory and everything below it
- One volume per user for mail delivery
- One volume per major application (e.g. Matlab, IDL etc.)
- One volume per architecture for locally added executables, etc.
Two special volumes always exist, and are replicated onto each file server for redundancy.
- root.afs: The top level directory in the AFS hierarchy. It
contains the mount points for the local root.cell volume, and for any remote cells
to which it may be desireable to connect.
- root.cell: The top level directory for the cell. All other volumes in the cell
are mounted below this point.
When a program opens a file, the AFS client must first look up the location of the volume
containing the file, then connect to the appropriate file server. When listing directory contents
containing many volume mount points, many database lookups are needed.
This metadata is cached, but performance can still be slow (e.g.
ls -l /afs/northstar/ufac). Unfortunately GUI file managers love to do this, frequently.
(7)
Scratch Volumes
AFS can be used for storage of data and temporary work files which do not need
to be backed up. To allow for this while keeping quotas on the home volumes
below a reasonable limit, we can create scratch volumes on request.
The tape backup system knows to skip over these, but otherwise they are treated
exactly as for any other volume.
- Backup snapshots created each night -- can be used to recover from accidental
deletions
- Stored on RAID disk on the servers, so protected against most hardware failures.
- Backup snapshots do not get sent to tape backup, but are overwritten each night.
Scratch volumes are usually mounted at /afs/@cell/nobackups/username
but can be mounted by the owner at any location which is convenient.
They are not subject to any automatic purging of old files, as is typically performed
on local /tmp or /scratch directories.
(8)
AFS filesystem layout
This figure shows approximately how the Northstar cell is laid out.
An indication of the permissions is also
shown. Other cells may differ radically.
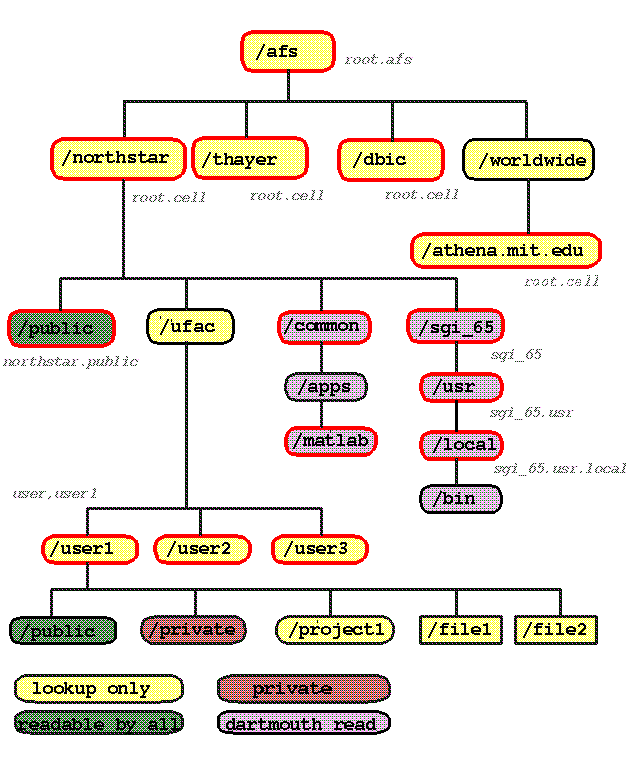
Figure 4. AFS filesystem layout. Red outlines are volume mount points.
Black outlines are plain directories.
User accounts are initally set up with two directories named private
and public. To facilitate file sharing between colleagues, the public
directory
allows public read access. All parent directories in the AFS hierarchy must allow a minmum
of lookup access to allow this to be used. This allows file names to be seen, but not contents.
The private directory is completely protected from all users other than the owner.
Changing the AFS ACL on a home directory is strongly discouraged as various
administrative functions may break. Newly created directories will inherit the
public lookup ACL of the parent, allowing any user to see the file names. Completely
private directories can be created with the 'fs setacl' command, or inside of the 'private'
directory.
The non-local cells have been split off to /afs/worldwide in order to improve performance
of GUI file managers which often try to retrieve information for every pathname component
from the root down. Listing /afs/worldwide is generally slow and may hang for long network
timeouts if remote cells are offline.
Special pathnames
/afs/@cell is a symbolic link to the local cell name , for convenience.
(/afs/northstar.dartmouth.edu)
/afs/northstar is a symbolic link to the fully qualified domain name, for convenience.
.../@sys/... in a pathname is replaced by the client architecture type
(e.g. sgi_65 for
IRIX 6.5 on SGI computers). This feature can be used to automatically select the correct set of
executables or configuration files for an application. For example, the system default
.cshrc and .login files will initialize the $PATH variable with architecture-specific
personal bin directories.
(9)
Access control (permissions)
Access control is handled at the directory level. All files in a
particular directory share the same permissions. Each directory has a set (up to 20) of
user permission pairs, which together are referred to as the Access
Control List or ACL.
The User in this sense is actually a
- single username
- AFS groupname, containing users or computer IP addresses.
The Permission in this sense is a combination of the following:
- r Read access to the files in this directory
- w Write access to the files in this directory
- i Insert access - can create files in this directory
- d Delete access - can delete files in this directory
- l Lookup access - can list the filesnames, and traverse the directory
- k locK access - can place advisory locks on files in this directory
- a Administer - can change the ACL on this directory.
The common combinations are "l" for lookup-only, "rl" for read permission and
"rlidwk" for read and write permission.
Three special groups exist and are commonly found in ACLs.
- system:anyuser All users, including ones with no token. This may imply worldwide
accessiblity if the directory can be reached.
- system:authuser Any user with a token for the cell
- system:administrators A short list of system administrators who have effective "root" access
to the AFS cell.
Access control is
more flexible than traditional Unix permissions, which only allow for a
single group; traditional Unix imposes access control at the file
level though. In practice the directory level controls are not a big
problem. Symlinks to subdirectories can be used if specific files need to have
different permissions. The Owner's mode bits are also used to control
access to a specific file. Group and Other bits are
not used.
Newly created directories inherit the ACL of the parent. The user's umask
(file mode creation mask) is still used for file creation, but only the 'user'
bits are relevant.
Default user accounts in the Northstar cell have two directories named public
and private. public allows any user to read, while private is inaccessible
to all but the owner.
Note that the home directories has public lookup access, to permit the public
directory to be reached.
Root-owned processes on a traditional Unix filesystem can read any
file regardless of permissions. This is not true with AFS homes.
A consequence of the directory-based ACLs is that hard links are only permitted for files
in the same directory. Hard links across directories would give rise to ambiguities
in access control.
(10)
Managing ACLs
ACLs are all managed by various options to the fs command. Wrapper scripts or aliases
for some of these may be available
fs_listacl (la)
- Displays the ACLs for one or more named files or directories. The default is "." (current directory).
fs_setacl (sa)
- Set the ACLs for one or more named directories. Multiple user permission pairs may be listed
Users are removed from the list by specifying none as the permission. Users are added to the existing ACL
unless the
-clear flag is also given.
fs_copyacl (ca)
- Copy the ACL from one directory to another. This allows a complex ACL to be set on a template directory and then
duplicated.
Negative ACLs
Access control is a logical OR of the user:permission pairs. Negative permissions can also be
specified with the -negative flag to fs setacl. This allows such settings
as "Any authenticated user in this cell (system:authuser), but not user 'bob'.
(11)
Group access controls
ACLs can contain groups in addition to individual usernames. Groups can be created, managed and deleted
by any user, using various options to the
pts command. Group names created by users have the form user:groupname
Wrapper scripts or aliases
for some of these may be available.
pts_creategroup
- Create a new group
pts_adduser
- Add one or more users to a group
pts_removeuser
- Remove a user from a group
pts_examine
- List details of a user of group. Groups have their own permssion flags which retrict who can list the
members, add or remove members etc.
pts_membership
- List the members of a group
pts_delete
- Delete a group.
The owner of a group determines who has rights to list membership, add users, remove users etc.
The owner is initially the creator, but may be reassigned. The owner can be the group itself (all members can have
administrative priviledges) or can be another group. For example, a smaller group of users can own
(and have administrative priviledges) a larger group.
(12)
Backup snapshots
The AFS system allows a snapshot to be taken of a volume at any point in time.
The main purpose of this is to 'freeze' a volume so that it can be transferred to
backup medium (tape etc.) in a self-consistant state. Backup snapshots are very quick and
efficient. Only files changed since the last backup snapshot are actually duplicated on disk.
We generate backup snapshots each night just after midnight (00:10). These are then
copied to the long-term
backup system, but the snapshot remains online until overwritten the next night. This means that
an accidentally deleted or corrupted file is actually still online in last night's snapshot.
Users can mount their own home volume backup snapshot (readonly) and retrieve files
without needing administrative priviledges. It is confusing to leave the backup volume mounted
permanently.
The procedure is:
fs mkmount ~/YESTERDAY user.myname.backup
YESTERDAY is now a read-only copy of your entire account as of last midnight. Files
can be copied out of it with all the usual Unix tools, but nothing can be modified
fs rmm ~/YESTERDAY (remove the temporary mountpoint)
Backup snapshots are migrated to tape each night. We take full backups monthly (kept
for 12 months) and incremental backups nightly (kept for 31 days).
(13)
Performance Tuning
Distributed fileservers
AFS fileservers can be distributed throughout the network, so that in an inhomogeneous
network environment, it is possible to have one or more servers more local in
a network sense. Arranging to have the most frequently accessed volumes from a particular
client on a close fileserver will improve performance.
Replicated Volumes
Volumes which are frequently read but only occasionally modified can be replicated
on multiple servers. Clients will automatically pick a read-only copy if one is available, and will
fail-over to a different copy if a server becomes unavailable. The top level volumes are usually
replicated on every file server in a cell.
Replicating the master (read/write) copy onto the read-only
copies is known as releasing the volume and is carried out manually,
using the release subcommand to vos (vos_release)
Large vs Small Volumes
Since volumes are the unit of AFS server space for transactions such as
migration between servers, replication, and backups,
many operations are easier if the size is kept smaller. The
important parameter is the ratio of the volume size to fileserver partition size.
The daily backup snapshots can cause the actual disk usage of a volume to be
double the visible space, if the files are modified daily. Large individual files make this
problem worse. Backup snapshots limit the fraction of a server that can be allowed to fill.
The tape backup system also requires staging space to hold the compressed backup snaphots, so
large, frequently updated volumes have a significant impact.
Smaller volumes: pro
- Easier to back up and restore
- Easier to migrate between servers for load balancing or maintenance
- More I/O bandwidth available, if the volumes are spread across multiple servers
Smaller volumes: con
- Moving files between volumes involves copying data. Moving files between directories
in the same volume is just changing a directory entry.
- Simpler (slightly) permission management. ACLs on a volume top level are very important.
It cannot be assumed to be protected by the ACL of a parent directory.
- Simpler quota management.
Client cache options
AFS performance is very dependant on the speed and configuration of the client. Upgrading client
CPU, disk, memory and networking all can have a large effect. The disk cache used on the client
should if possible be on a disk partition of its own, ideally on a striped local filesystem. The
client cache manager has various startup options which control how much memory it uses, and how much metadata
related to volumes, directory entries and file data are kept cached locally. Increasing those values
generally improves performance, but there is a point at which performance suffers because of searching times.
The amount of file data transferred in one transaction (chunk size) can be tuned. Well connected fast
networks with few lost packets will benefit from larger chunk sizes than the default. Graphical file
managers will benefit from larger amounts of file and directory metadata in cache.
(14)
Installing AFS clients
The installers and source code for all supported platforms are at
OpenAFS.org. Unfortunately the documentation available largely dates
from the IBM/Transarc AFS 3.6 release and is out of date in many respects.
Common to all platforms are the need to configure the following items for each client
- Default cell (traditionally /usr/vice/etc/ThisCell; must be set)
- CellServDB file (may be optional on some platforms now)
- AFS mount point (traditionally /afs)
- Client cache details (size and location, may be left at default values)
- Optional client daemon parameters to improve performance
The client parameters are passed to the client AFS daemon processes at startup and determine
such things as the size and type (memory or disk) of the cache,
size of the file chunks passed over the network, and
the sizes of various file metadata caches. In general the default values are very conservative
and performance gains can be made by increasing them, at some expense in memory usage.
The CellServDB file (legacy) is used to provide the IP addresses of the database servers
of the cells to which you may want to connect. The same information is usually provided
by the DNS service mechanism, but not all
cells use DNS, and older clients did not support it. The DNS provides a special record type to return
the AFS server addresses associated with a given cell name. The CellServDB file takes precedence, so it
must not contain incorrect information.
Traditional Unix platforms
The traditional Unix platforms (Solaris, Irix, AIX etc.) use compressed tar files
for the installation mechanism. When unpacked, they create the following directories:
bin, etc, include, lib - to be installing via copying or linking below /usr/afsws.
Also root.client, root.server which contain the client modules and configuration
(/usr/vice) and server software (/usr/afs). The various daemons and kernel modules are loaded through
startup scripts in the standard ways (/etc/init.d/afs). Default cell, client cache manager
configuration and CellServDB files must be edited after installation.
Linux
For Linux, the software was broken into modules and repackaged as RPM files. Which RPMs
are needed depends on whether you want to install client, server, or both, and whether you need to be
able to build from source. The naming scheme is generally openafs-susbsystem-vers-distrib-arch.rpm
For example:
openafs-1.2.13-rhel3.0.1.i386.rpm All
openafs-1.2.13-rhel3.0.1.src.rpm All devel.
openafs-client-1.2.13-rhel3.0.1.i386.rpm Client
openafs-compat-1.2.13-rhel3.0.1.i386.rpm Client (opt)
openafs-debuginfo-1.2.13-rhel3.0.1.i386.rpm All devel.
openafs-devel-1.2.13-rhel3.0.1.i386.rpm All devel.
openafs-kernel-1.2.13-rhel3.0.1.i386.rpm Client
openafs-kernel-source-1.2.13-rhel3.0.1.i386.rpm Client devel.
openafs-kpasswd-1.2.13-rhel3.0.1.i386.rpm
openafs-krb5-1.2.13-rhel3.0.1.i386.rpm All devel.
openafs-server-1.2.13-rhel3.0.1.i386.rpm Server
After installation, the default cell, cache configuration and CellServDB files must be edited by hand.
Mac OS-X
The installer for Mac OS 10.1 and later is a native OS-X package format which installs with no
special information required from the user (admin priviledges are required).
The software is installed into /var/db/openafs (cache and configuration)
and /Library/OpenAFS/Tools (all user tools and libraries). The user tools
in /Library/OpenAFS/Tools/bin are symlinked to /usr/bin, but the administrator tools
in /Library/OpenAFS/Tools/etc are not in the $PATH by default.
The /usr/afsws directory is not used - it can be symlinked if necessary to support scripts
with hard coded paths to /usr/afsws/bin. After installation, the default cell, cache configuration and
CellServDB files must be edited by hand. The default cache is 30 MB.
Microsoft Windows
The windows (NT-based, Win2k and newer) installer is a single .exe file
which prompts for user input about which components to
install. In general only the client is needed. The optional extended documentation is the same
as available at OpenAFS.org and is out of date. The client software is installed into
C:\Program Files\OpenAFS, along with many additions to the registry. An uninstaller
in also provided. Command line tools are also made available in the %PATH% after installation.
A client tool is provided to create Windows drive mappings to AFS pathnames, e.g.
F: -> \afs
G: -> \afs\northstar.dartmouth.edu\ufac\afsusername
During installation, the default cell name (e.g. northstar.dartmouth.edu) is requested, and also
an initial CellServDB file. An option is provided to
download a file from a URL:
http://northstar-www.dartmouth.edu/doc/restricted/CellServDB can be used.
Windows AFS client uses the DNS (AFSDB) method to locate servers by default, so a CellServDB file may not be
needed.
The other options can be left at their default settings. After reboot, the AFS client software will
be running, but AFS will not be accessible until drive mappings have been made. Some of the settings
are systemwide (admin users only) and some are per-user. Open "Control Panel:Other Control Panel Options:
AFS Client Configuration" to set up drive letter mappings and optionally adjust cache size and other
parameters. The default cache is 100 MB.
If Windows logins are configured using kerberos-5 and a username/password database which is
synchronized with the AFS usernames, tokens may be automatically obtained at login time.
This is not the case at Dartmouth.
The release notes for Windows contain many caveats about incompatabilities between Windows and Unix.
Many of the new features in the Windows clients are to support mobile users with changing
network connectivity and addresses (freelance mode, or Dynamic Root - cells are not mounted
until they are referenced).
Windows explorer will display additional AFS properties (ACL settings etc.) for folders in AFS
(right-click)
Older versions of the AFS client are supported on Windows 9x and NT4, but are no longer maintained or
developed.
www.dartmouth.edu/comp/support/library/research/unix/files/afs/clients.html has
local notes on installing AFS on various platforms (also out of date in many places).
(15)
Challenges with mobile clients
- Mostly robust to non-continuous network connection (UDP/RX based, not TCP)
- DHCP addresses OK
- Private addresses OK, as long as they are routed to the servers
- Mobile clients changing IP address will appear to the server to be
a new client
- Switching between wired and wireless networks may present problems
- Wireless network and laptops can sometimes have startup issues
(16)
Mac OSX client
- Natively integrates with the finder for most operations
- Need to
klog in a Terminal window
- Mounting and unmounting AFS
- Wireless client startup delays
- Administrative tools all command line, as for Unix
- Third-party add-on tools available
(17)
Selected parts of AFS documentation
The top level of the OpenAFS documentation set is at
klog
tokens
unlog
pagsh
fs
fs_listquota
fs_examine
fs_flush
fs_flushvolume
pts
pts_creategroup
pts_adduser
pts_removeuser
pts_examine
pts_membership
pts_delete
kpasswd
fs_listacl
fs_setacl
fs_copyacl
vos
vos release
(18)
Locally added AFS Commands
AFS commands are not intuitive so some Dartmouth-specific scripts have been written to
hide some of the command details.
| Function/Action |
Command |
|
Check your disk space (quota) for your home directory.
|
quota or afsquota
|
|
Set permissions (ACL) on a group of files, or recursively in a directory tree
|
setacl [-R] [-v] who,what directory [directory]
|
|
Copy permissions (ACL) from a group of directories to another tree
|
copyacl [-R] [-v] source-directory target-directory
|
(19)
References, Resources, Man pages etc.
Books
- Managing Afs: The Andrew File System by Richard Campbell.
More info
Online Resources
(will open in a separate window)
- OpenAFS (http://www.openafs.org/)
OpenAFS home page
- openafs-info mailing list archives
(http://www.mail-archive.com/openafs-info@openafs.org/)
Searchable archives of the openafs-info mailing list
- Grand Central (http://www.central.org/)
A community resource for users of the AFS distributed file system.
- AFS lore Wiki
(http://www.central.org/twiki/bin/view/AFSLore/WebHome)
A web-based collaboration area for collecting, maintaining, and distributing information about the
AFS distributed filesystem and related topics.
- Introduction to AFS and its Administration
(http://www.pmw.org/afsbpw05/afstut.html)
Slides from an AFS and Kerberos Best Practices Workshop held at CMU in Jun 2005.
Academic site AFS information
Related Software
- The ARLA project
(http://www.stacken.kth.se/projekt/arla/)
An AFS client implementation independant of
Transarc and OpenAFS.
- The CODA project
(http://www.coda.cs.cmu.edu)
An AFS spinoff designed for mobile clients.
Using OpenAFS effectively: Course Handout
(last update 09 February 2011) ©Dartmouth College
http://www.dartmouth.edu/~rc/classes/afs